
[this blog is based on my new project located here https://github.com/planglois925/intel-grapher ]
While relationships are often complex, there’s sometimes a lot of value that you can get from deeply examining relations in a standardized fashion. A relatively new comer in the database world, graph databases, allows just that through a flexible means of capturing and describing relationships between different elements. This blog will look at how threat analysts (or really any form of analyst) can leverage graph databases to help them with their analysis.
Graph Databases:
So graph database are a sub-set of NoSQL databases, which as the name describes, aren’t structured according to SQL, pretty intuitive. One of the more common NoSQL databases, MongoDB allows the ability to structure the data as “Documents”, which in essence are just JSON , I know a gross oversimplification. One of the advantages behind a NoSQL database is that there isn’t a need for a rigid data structure that needs to be created and migrated as the data model becomes more complex. For Mongo you don’t necessarily need to know how your data is structured, which is useful for data like logs which may change as developers add new functionalities and data elements.
In my really uneducated opinion on the topic, Graph Databases serve as that middle point between fully unstructured data + SQL based databases. Everything in a Graph database is either a NODE or a RELATIONSHIPS (links), which connects Nodes and can have their own attributes.
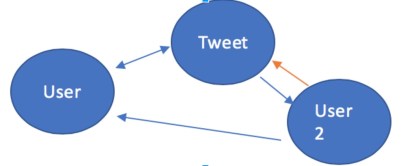
In our simple example above we can there is a BIDIRECTIONAL relationship between Node 1 and 2, unidirectional relationship between 3 to 1 and 2 to 3. And lastly there’s another unidirectional relationship between Node 3 and 2, which is different from the other relationships. Each of these Nodes could be used to describe some form of entity, such as a Person, IP Address, Email Address, Tweet, Hashtag, etc. Relationships also provides this level of flexibility and can be used to describe any type of relationship such as, Messaged, Resolves to, Hosts, Tweeted, Retweeted, Liked, Replied, etc.
You can start to put the pieces together using grammar, Nodes are probably going to be the Nouns and Relationships probably will describe the verb that occurs between these messages. Twitter user 1 tweeted Tweet 2 which was retweeted by Twitter User 2. As you can imagine storing and querying this type of information can be extremely useful when trying to put the pieces of different data together from different sources, such as when you take an indicator and enhance it with data from a third-party service.
Hopefully by now you’ve realized the Graph Databases are perhaps the best thing ever in the history of technology and will revert all your projects to using exclusively this (a statement dripping with sarcasm). While it has its upside it also has its downsides, which I will cover on a future blog post, however, threat intelligence or really any data enhancement process can benefit to help connect the dots between the seemingly disparate data. There’s a reason why the most popular OSINT tool Maltego uses graphs to show their data, which is the tool I was trying to replicate when tackling this project.
QUICK WORD ABOUT A LOT OF DATA
So while Graphdbs are really neat to play with, there are limitations with the scalability and may not be appropriate for larger data sets. One way around that, is storing the data into flatfiles and importing them into the tools when you need them.
Our Project Idea
The idea behind our tool is that we want to be able to take specific types of data (Twitter User, email address, IP address, domain, etc.) and enrich it through the use of third party services (Twitter, Virus Total, Shodan, etc) and save this in way that we can query it and examine. For our uses we’ll look to use to Neo4j as the graph database backend and python as the data enricher. Eventually we may want to create a fancy front end it to make it easier to modify query the data beyond the built in functionalities of the Neo4j, but that’s a whole different ball game.
Our process is going to be as following
- Give script the data you want to enhance
- Send out API request
- Parse data into appropriate format
- Input data into neo4j
As mentioned, we will be using Neo4j as our backend and we will be using Docker to make it nice self contained backend. First you’ll have to install Docker and then download the Neo4j image. Once you have that in place, you can spin it up using this command
docker run \
–publish=7474:7474 –publish=7687:7687 \
–volume=$HOME/neo4j/data:/data \
neo4j
Neo4j uses a couple different ports, the first of which is the Bolt on port 7687 which allows for remote services to upload data and also there’s a relatively robust web interface on 7474 that allows you to make queries and do all the fun stuff. When you boot up your docker instance, you should be able to access the web interface on localhost:7474. Once you log in I highly recommend you check out the built in tutorial to get a starting grasp of Cypher, the ASCII based query language for Neo4j, but we’ll be going more into depth with that later on.

So now that you have your backend stood up, the next step in the process is developing your data enhancement process. In essence, you want to be able to take in some indicator, enrich it, then store those results in the database. The neat thing with Neo4j is since everything in it is simply either a Relationship OR Node, we can standardize that element of the process across all our tools and create a generic class that can be inherited by all the other pieces
We’ll pick a relatively simple data enrichment service, ThreatCrowd as our first process. I’ll be using the following libraries as part of the code. Py2neo will be our library to interact with Neo4j.
Enhancing Data
While for many popular services you can find and access modules and libraries to help you integrate with existing API’s, it’s also important that you learn how to create your own, which is what we’ll be doing. The API for the ThreatCrowd is relatively simple, but it does provide back different types of data, such as associated email addresses, domains, IPs, file hashes and more. As such we’ll probably want to define a label for each type of data we can get back AND a label for each type of relationship. So if we give it a domain and our response gives us an IP address, we’d want that relationship to be captured differently than if we got back an email address or file hash. For these I create a relatively a simple table that will help me keep track of my relationships
| Origin | Destination | Relationship |
| Domain | IP Address | Resolves |
| Domain | Sub-domain | Hosts |
| Domain | Email Address | Registrar |
Based on this list I know I’m going to have create Nodes with a specific label of domain, IP_address, Sub-Domain and email address.
Creating our Core
Since we have various types of Nodes and various types of Relationships, we’ll want to make a generic object that can be leveraged by each of the different apps we’ll be creating. For this, start off by creating a module (so a directory with a __init__.py file in it). This module will contain our generic NodeBuilder class and RelationshipMaker class. So the code below will show you how that will look like.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| from py2neo import Graph, Node, Relationship | |
| class NodeCreator: | |
| def __init__(self): | |
| ''' | |
| Start off my creating the graph connection | |
| If you're making a new Node label define it here, along with it's abbreviation | |
| ''' | |
| #CHANGE ME TO WHATEVER YOURS IS | |
| self.graph = Graph(password="password") | |
| self.Node_Label = "" | |
| self.Node_abrev = "" | |
| self.node_fields = [] | |
| self.Plugin_name = "" | |
| self.node_key_field = "" | |
| def create_or_update(self, key, data=None): | |
| """ | |
| Method to create or update a node. | |
| :param key: THe unique key value that you want to add or update | |
| :param data: The data that you want to be added to the node | |
| :return: | |
| """ | |
| node = self.graph.find_one(self.Node_Label, 'id', key) | |
| if node is None: | |
| self.create_node(key,data) | |
| else: | |
| self.update_node(data=data, key=key) | |
| def create_node(self, key, data=None): | |
| """ | |
| Method to add a new node to the graph database | |
| :param key: The unique key value that you want to use to add | |
| :param data: The data you want to add | |
| :return: | |
| """ | |
| if data is None: | |
| node = Node(self.Node_Label, id=key) | |
| print 'creating node %s' % key | |
| else: | |
| node = Node(self.Node_Label, id=key) | |
| node.update(data) | |
| self.graph.create(node) | |
| def update_node(self,data, key): | |
| node = self.graph.find_one(self.Node_Label, 'id', key) | |
| node.update(data) | |
| class RelationshipMaker: | |
| def __init__(self): | |
| ''' | |
| Start off my creating the graph connection | |
| If you're making a new Node label define it here, along with it's abbreviation | |
| ''' | |
| self.graph = Graph(password="password") | |
| self.Relationship_Label = "" | |
| self.node_fields = [] | |
| self.Plugin_name = "" | |
| self.Bidirectional = False | |
| self.from_node_type = "" | |
| self.to_node_type = "" | |
| def make_relationship(self, from_node, to_node, data=None): | |
| relationship = self.Relationship_Label | |
| print 'search for %s' % to_node | |
| from_nodes = self.graph.find_one(self.from_node_type, 'id', from_node) | |
| end_node = self.graph.find_one(self.to_node_type, 'id', to_node) | |
| print "found %s" % from_nodes | |
| print "found end: %s" % end_node | |
| if from_nodes != None and end_node != None: | |
| rel = Relationship(from_nodes, relationship, end_node) | |
| if data: | |
| for key, value in data.iteritems(): | |
| rel[key] = value | |
| self.graph.create(rel) | |
| else: | |
| print "failed to find %s" % from_node |
As you can see there’s a few methods that we want to have for our Node creator. We want to have logic that states if this node is new, create it, otherwise update it. This will stop us from creating duplicate nodes and updating ones that already exist in our data. For each node, we want to define what our key field is, this is most likely something that is going to be consistently unique for each node, think of a email address, IP address, screen name kind of deal.
Next you’ll want to create your relationship maker. Since I want to be consistent with my use of labels of relationships, I’m going to enforce a few things. First off, I want relationships of a specific label, to only be able to join the Nodes of the right kind. So I want to make sure my Resolves relationship, is joining a Domain to a IP address and in that order. So thats what you can see with how we structure our relationships.
Creating our Data Enhancement modules
Now that we have our core built out, we can start to building out the data the process we want that we want to use to get our data. These modules are going to be relatively simple and will contain only two files (not counting the __init__.py). The first file we can call threatcrowd, this one will contain our types of nodes + relationships, and utils which contain the actual data enhancement piece. Below is the module that contains our nodes and relationships
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| from core.modules import NodeCreator, RelationshipMaker | |
| from py2neo import Graph | |
| class EmailTC(NodeCreator): | |
| def __init__(self): | |
| NodeCreator.__init__(self) | |
| self.Node_Label = 'Email' | |
| self.Plugin_name = 'ThreatCrowd' | |
| self.node_key_field = 'email_address' | |
| class DomainTC(NodeCreator): | |
| def __init__(self): | |
| NodeCreator.__init__(self) | |
| self.Node_Label = 'Domain' | |
| self.Plugin_name = 'ThreatCrowd' | |
| self.node_key_field = 'domain' | |
| class Sub_DomainTC(NodeCreator): | |
| def __init__(self): | |
| NodeCreator.__init__(self) | |
| self.Node_Label = 'Sub-Domain' | |
| self.Plugin_name = 'ThreatCrowd' | |
| self.node_key_field = 'sub-domain' | |
| class IP_addressTC(NodeCreator): | |
| def __init__(self): | |
| NodeCreator.__init__(self) | |
| self.Node_Label = 'IP_address' | |
| self.Plugin_name = 'ThreatCrowd' | |
| self.node_key_field = 'ip_address' | |
| class Hashes_TC(NodeCreator): | |
| def __init__(self): | |
| NodeCreator.__init__(self) | |
| self.Node_Label = 'Hashes' | |
| self.Plugin_name = 'ThreatCrowd' | |
| self.node_key_field = 'Hashes' | |
| #Relationships | |
| class Domain_to_IP_address(RelationshipMaker): | |
| def __init__(self): | |
| RelationshipMaker.__init__(self) | |
| self.Relationship_Label = "Resolves" | |
| self.to_node_type = "IP_address" | |
| self.from_node_type = "Domain" | |
| class Domain_Sub_domain_Relationship(RelationshipMaker): | |
| def __init__(self): | |
| RelationshipMaker.__init__(self) | |
| self.Relationship_Label = "Hosts" | |
| self.to_node_type = "Sub-Domain" | |
| self.from_node_type = "Domain" | |
| class Email_Domain_TC_Relationship(RelationshipMaker): | |
| def __init__(self): | |
| RelationshipMaker.__init__(self) | |
| self.Relationship_Label = "Owns" | |
| self.to_node_type = "Domain" | |
| self.from_node_type = "Email" | |
| class Domains_Hashes_Relationship(RelationshipMaker): | |
| def __init__(self): | |
| RelationshipMaker.__init__(self) | |
| self.Relationship_Label = "Associated" | |
| self.to_node_type = "Hashes" | |
| self.from_node_type = "Domain" | |
| class Hashes_IP_Address_Relationship(RelationshipMaker): | |
| def __init__(self): | |
| NodeCreator.__init__(self) | |
| self.Relationship_Label = "Associated" | |
| self.to_node_type = "Hashes" | |
| self.from_node_type = "IP_address" | |
| class Hashes_Sub_Domain_Relationship(RelationshipMaker): | |
| def __int__(self): | |
| RelationshipMaker.__init__(self) | |
| self.Relationship_Label = "Associated" | |
| self.to_node_type = "Hashes" | |
| self.from_node_type = "sub-domain" |
The code above is our modules, pretty simple stuff, it just defined what kinds of nodes and relationships we’d be anticipating. Keep an eye on the relationship nodes as those will need to be in order to properly function, the order between the to and from nodes need to be maintained.
Utils
The first step you’d want to do is import all the modules we made and a couple additional libraries, such as Requests. For those who haven’t used Requests, it’s an awesome library that allows to quickly make HTTP requests and process the resulting data. The first thing that we’ll want to do is call in our objects both the nodes and relationships and define the API endpoint that we’ll be using. In this case our endpoint is Threatcrowd. Doing a little research we’ll identify the what information that api needs, for our super simple example we’ll hardcode most of those values, but that’s not always the best option.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def add_domain_lookup(domain): | |
| # Add the nodes | |
| domain_maker = modules.DomainTC() | |
| hash_maker = modules.Hashes_TC() | |
| email = modules.EmailTC() | |
| sub_domain = modules.Sub_DomainTC() | |
| ip_address = modules.IP_addressTC() | |
| # add the relationships | |
| domain_to_hash = modules.Domains_Hashes_Relationship() | |
| domain_to_sub_domain = modules.Domain_Sub_domain_Relationship() | |
| domain_to_email = modules.Email_Domain_TC_Relationship() | |
| domain_to_ip = modules.Domain_to_IP_address() | |
| # add the domain | |
| domain_maker.create_or_update(key=domain) | |
| # Do the look up | |
| data = get_TC_domain(domain) | |
| if data: | |
| if data['emails']: | |
| for email_address in data['emails']: | |
| email.create_or_update(email_address) | |
| domain_to_email.make_relationship(to_node=domain, from_node=email_address) | |
| if data['resolutions']: | |
| for resolve in data['resolutions']: | |
| resolved = {} | |
| resolved['last_resolved']= resolve['last_resolved'] | |
| ip_address.create_or_update(key=resolve['ip_address'], data=resolved) | |
| domain_to_ip.make_relationship(from_node=domain, to_node=resolve['ip_address']) | |
| if data['hashes']: | |
| for hashes in data['hashes']: | |
| hash_maker.create_or_update(key=hashes) | |
| domain_to_hash.make_relationship(from_node=domain, to_node=hashes) | |
| if data['subdomains']: | |
| for subdomains in data['subdomains']: | |
| sub_domain.create_or_update(key=subdomains) | |
| domain_to_sub_domain.make_relationship(from_node=domain, to_node=subdomains) | |
| else: | |
| pass |
As you can see in our code we’re going through, making our request, processing our data and then inputting our data into our objects using some nifty loops. You should know be able to see all the data in your database if you did right.
Now we’ll just want to add a script that we can start and give it a few arguments to parse and we’re good to go.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| from threatcrowd import utils as tc_utils | |
| import argparse | |
| def main(): | |
| parser = argparse.ArgumentParser(description='Tool to take data and insert it into graphdatabase') | |
| parser.add_argument('-d', '–domain', help="Domains to look up", default=None) | |
| parser.add_argument('-e', '–email',help='Emails to look up', default=None) | |
| parser.add_argument('-hx', '–hash', help='Hashes to look up', default=None) | |
| parser.add_argument('-i', '–ip', help='IP address to look up', default=None) | |
| args = parser.parse_args() | |
| if args.domain: | |
| tc_utils.add_domain_lookup(args.domain) | |
| if args.email: | |
| tc_utils.add_email(args.email) | |
| if args.hash: | |
| tc_utils.add_file_hash(args.hash) | |
| if __name__ == '__main__': | |
| main() |
And bam, you have yourself a data enhancement tool powered with a graphdatabase. The nice thing about this model and approach is that it’s trivial to go and create any new type of data enhancement module, as long as there’s an api that you can query the data with. I’m always interested in helping to make this more useful for other people, so don’t hesitate to drop a ticket or add a pull request with your own favorite modules or tools that you use.
Thanks for reading!
-PL
